Summary: In the current scenario, biological data is so huge that biologists depend on databases to store, organize, search and analyze data. In DNA databases efforts are made to store data of DNA sequences which are potentially useful for computation. With the fast pace of advancement of technology in the field of bioinformatics, India is not behind from other countries. Substantial efforts have been done to store sequence data. There are several databanks and softwares available on internet for retrieving information and among them, GenBank/EMBL/DDBJ databank stores largest number of records.
Introduction
When the thought of database arises in our mind, we think of two basic important functions. Firstly, storing of large and scattered data and secondly, a retrieval system which has ability to perform various statistical operations on stored data. In DNA databases efforts are made to store data of DNA sequences, potentially useful for computation. When a new DNA sequence is obtained, there is desire to know, whether this DNA sequence already exist or it is a new one. This can be searched in databases to know its originality. DNA Databases are helpful to get the annotations of specific sequences which helps in research work. Also, biological data is so huge that biologists depend on databases to store, organize, search and analyse data. In this paper an effort is made to provide an idea about bioinformatics, types of databases, highlight some of the facilities available on internet for searching DNA databases.
Bioinformatics
Bioinformatics is about bringing biological themes together with the help of computer tools. It is a new field of science where mathematics, computer science and biology combined together to study and interpret genomic information. But unfortunately, the awareness about this branch of science is poor among the common man, students & teachers at schools, colleges and universities, except of course, those who deal with it.
Types of Databases
There are various types of databases to store information about biological patterns of DNA. Most of these databases contain evolving information and therefore have gone through several revisions, since they were first introduced. With the advancement of technology, a number of new software for DNA computing has been developed in the field of computer. A pictorial representation of database types is shown below.
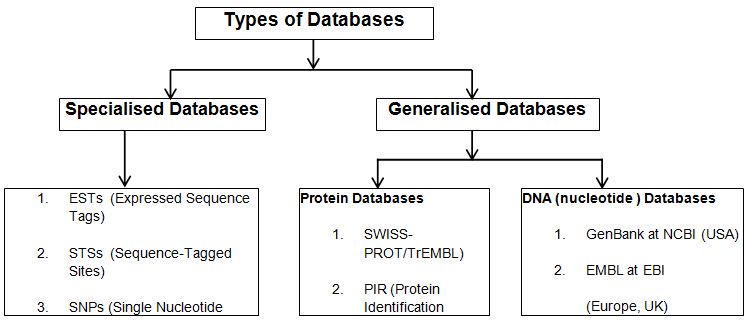
Databases are of two types: Specialised databases and Generalised databases. Some of the specialised databases are Expressed Sequence Tags (ESTs), Sequence-Tagged Sites (STSs) and Single Nucleotide Polymorphisms (SNPs). Generalised databases consists of two main classes: DNA Nucleotide Databases and Protein Databases. Some of the DNA Nucleotide Databases are GenBank at NCBI (USA), EMBL at EBI (Europe, UK) and DDBJ (Japan). Protein Databases consist of databases having high level of annotations. Some of them are SWISS-PROT/TrEMBL) and Protein Identification Resource (PIR).
Online Facility in Genome Research
Internet has played a significant role in providing information about different biological softwares to the scientists in very limited cost and time. There are few widely used archives of biosciences software. Two commonly used archives of molecular biology software are IUBio Archive, at Indiana University and the European Bioinformatics Institute (EBI) software archive. The European Bioinformatics Institute (EBI) is home of EMBL databank and many other large molecular biology software archive. The IUBio Archive is also collection of biology software and also provides services for keyword searching from GenBank, Swissprot and PIR databanks. Some of the important databanks are listed below:
1. GenBank
GenBank is DNA Sequence database of National Center for Biotechnology Information (NCBI). The NCBI assumed responsibility for the GenBank DNA sequence database in October, 1992. GenBank database has been built from sequences submitted by individual laboratories and by data exchange with the international nucleotide sequence databases, European Molecular Biology Laboratory (EMBL) and the DNA Database of Japan (DDBJ).
2. DDBJ (DNA Databank of Japan )
The DDBJ began DNA data bank activities in earnest in 1986 at the National Institute of Genetics (NIG). The DDBJ has been functioning as the international nucleotide sequence database in collaboration with EBI/EMBL and NCBI/GenBank.
DNA sequence records organismic evolution is invaluable not only for research in life sciences but also human welfare in general.
3. EMBL (European Molecular Biology Laboratory)
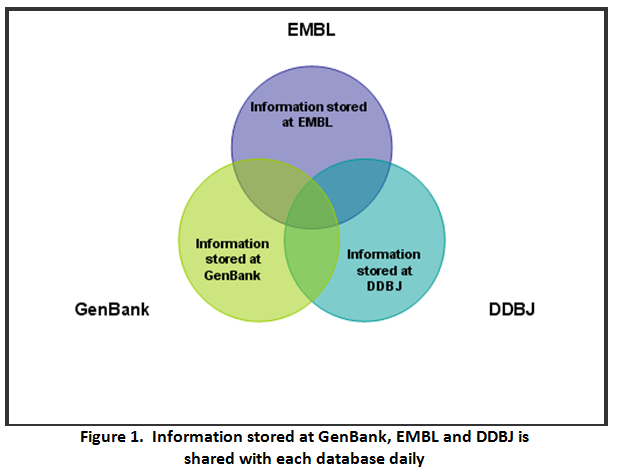
The EMBL Nucleotide Sequence Database is Europe's primary nucleotide sequence data resource. The EMBL is a central activity of the European Bioinformatics Institute (EBI). It was first established in 1980 to collect, organize, and distribute a database of nucleotide sequence data and related information. Since 1982 this work has been done in collaboration with GenBank (NCBI) and DDBJ. Each of the three groups collects a portion of the total sequence data reported worldwide, and all new and updated database entries are exchanged between the groups on a daily basis. There is an ongoing collaboration between the EMBL and the major sequencing projects producing large quantities of data.
Patrica Rodriguez-Tome (2000) reported “Because of the high throughput sequencing technology used in many centers, sequences are being deposited currently in the EMBL database at a rate of one sequence per minute”.
Indian Efforts in Bioinformatics
With the advancement of technology all over the world in genomics, India has also tried hard effort to improve the bioinformatics activities of the country. Some of the efforts done in India to enhance bioinformatics are highlighted here:
1. The Department of Biotechnology, Govt. of India has established several internationally recognized databases in India under the National Jai Vigyan Science & Technology Mission for Genomic Research. These databases are set up at Indian Institute of Science (IISc), Bangalore; University of Pune, Pune; Jawaharlal Nehru University (JNU), New Delhi and Institute of Microbial Technology (IMTECH), Chandigarh. The Databases will be in the form of Mirror Sites, of Genome Databank (GDB), Protein Database (PDB), Plant genome Databases and Databases and Software hosted at European Bioinformatics Institute (EBI). The advantage of mirroring these databases from India will be to provide unhindered access to large amount of databanks for analysis of not only the primary information but also the secondary information resources. Important research leads are expected to be generated through in-depth analysis of such data and it is hoped that these Mirror sites will act as knowledge pathways for discoveries in modern biology and biotechnology. The following are the URLs for some of these sites which have started functioning: GDB: pranag.physics.iisc.ernet.in; PDB: iris.physics.ernet.in and EBI: bioinfo.ernet.in. The other URLs and change of URLs can be viewed at the department's web site http://www.nic.in/dbt
2. An EMBnet node was also considered for India and Mirrored at Centre for DNA Fingerprinting and Diagnostics (CDFD), Hyderabad. It provides in-house services for the comparison and analysis of sequence/genome data, protein 3-D modeling and molecular graphics. The research interests focus on protein sequence and structure analysis, protein modeling, drug design, genome analysis and databases. The URL for this site is http://www.cdfd.org.in/.
3. Another major step has been the establishment of a Biotechnology Information System (BTIS), in the form of a National Bioinformatics Network. India was one of the first countries to establish a nation-wide Bio-information System. The Department of Biotechnology took this major leap forward with the mission to make India a leader in Bioinformatics. The Biotechnology Information System (BTIS) Programme was launched during the 7th Five Year Plan (1987-1992) to harness the scientific knowledge in various inter-disciplinary areas of biotechnology. The programme consists of a distributed database and network system, namely the Biotechnology Information System Network (BTISnet). Under the BTISnet, Distributed Centres were located in cities and institutes where active research work in the area of biotechnology was in progress. In the second phase, several sub-centres were established in various universities and research institutes that were running major biotechnology programmes and projects. Computer hardware to carry out simple data analysis and modeling is also available through this programme.
Conclusion
With the fast pace of advancement of technology in the field of bioinformatics, India is not behind from other countries. And very soon India can reach at the position when bioinformatics will be practiced in all schools, colleges and universities in great detail. There are several databanks and softwares available on internet for retrieving information and among them, GenBank/EMBL/DDBJ databank stores largest number of records. The most important point is that the information stored with any of them is shared among them on daily basis. This helps to keep databank updated and without duplication
References:
1. Jenuth JP (2000) The NCBI. Bioinformatics Methods and Protocol Edited by Stephen Misener and Stephen A. Krawetz. Methods in Molecular Biology 132: 307.
2. Kari L and Landweber LF ( 2000) Computing with DNA. Bioinformatics Methods and Protocol Edited by Stephen Misener and Stephen A. Krawetz. Methods in Molecular Biology 132 418-420.
3. Stoesser G, Moseley MA, Sleep J, McGowran M, Garcia-Pastor M and Sterk P (1998) The EMBL nucleotide sequence database. Nucleic Acids Res. 26: 8-15.
4. Tome PR (2000) Resources at EBI. Bioinformatics Methods and Protocol edited by Stephen Misener and Stephen A. Krawetz. Methods in Molecular Biology 132: 313,319.
5. Don Gilbert (2000). Free Software in Molecular Biology for Macintosh and MS Windows Computers. Bioinformatics Methods and Protocol edited by Stephen Misener and Stephen A. Krawetz. Methods in Molecular Biology 132: 149-184.
6. Francis Ouellette (2000). Biological Databases: Defining and Building. Current topics in Genome Analysis.
7. Prabhu G. Nagendra, Biotechnology & The Indian Initiatives
8. http://www.DDBJ.com/- website of DNA Databank Japan
9. http://www.NCBI.com/- website of National Center for Biotechnology Information
10. http://www.EMBL.com/- website of European Molecular Biology Laboratory
About Author / Additional Info:
I am a Scientist (Computer Application) at National Bureau of Plant Genetic Resources.